

Spark (스파크)
스파크는 크게 두가지로 구성됩니다. 작업을 관리하는 드라이버와 작업이 실행되는 노드를 관리하는 클러스터 매니저입니다
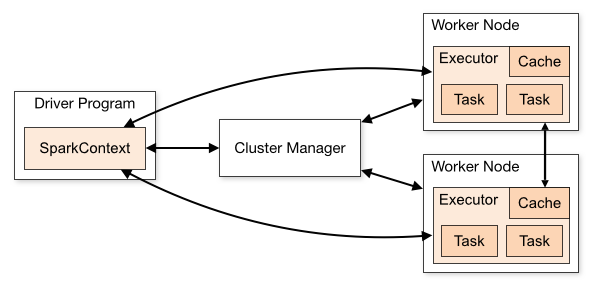
스파크 애플리케이션
스파크 실행 프로그램으로 드라이버와 익스큐터 프로세스로 실행되는 프로그램을 말합니다. 클러스터 매니저가 스파크 애플리케이션의 리소스를 효율적으로 배분하게 됩니다.
드라이버(Driver)
스파크 드라이버는 스파크 애플리케이션을 실행하는 프로세스입니다. main 함수를 실행하고, 스파크 컨텍스트(SparkContext) 객체를 생성합니다. 스파크 애플리케이션의 라이프 사이클을 관리하고, 사용자로 부터 입력을 받아서 애플리케이션에 전달합니다. 작업 처리 결과를 사용자에게 알려줍니다.
드라이버는 실행 시점에 디플로이 모드를 클라이언트 모드와 클러스터 모드로 설정할 수 있습니다. 클라이언트 모드는 클러스터 외부에서 드라이버를 실행하고, 클러스터 모드는 클러스터 내에서 드라이버를 실행합니다.
익스큐터(Executor)
태스크 실행을 담당하는 에이전트로 실제 작업을 진행하는 프로세스입니다. YARN의 컨테이너 라고 볼 수 있습니다. 익스큐터는 태스크 단위로 작업을 실행하고 결과를 드라이버에 알려줍니다. 익스큐터가 동작 중 오류가 발생하면 다시 재작업을 진행합니다.
태스크(Task)
익스큐터에서 실행되는 실제 작업입니다. 익스큐터의 캐쉬를 공유하여 작업의 속도를 높일 수 있습니다.
스파크 잡의 구성
스파크 애플리케이션의 작업은 잡(Job), 스테이지(Stage), 태스크(Task)로 구성됩니다.
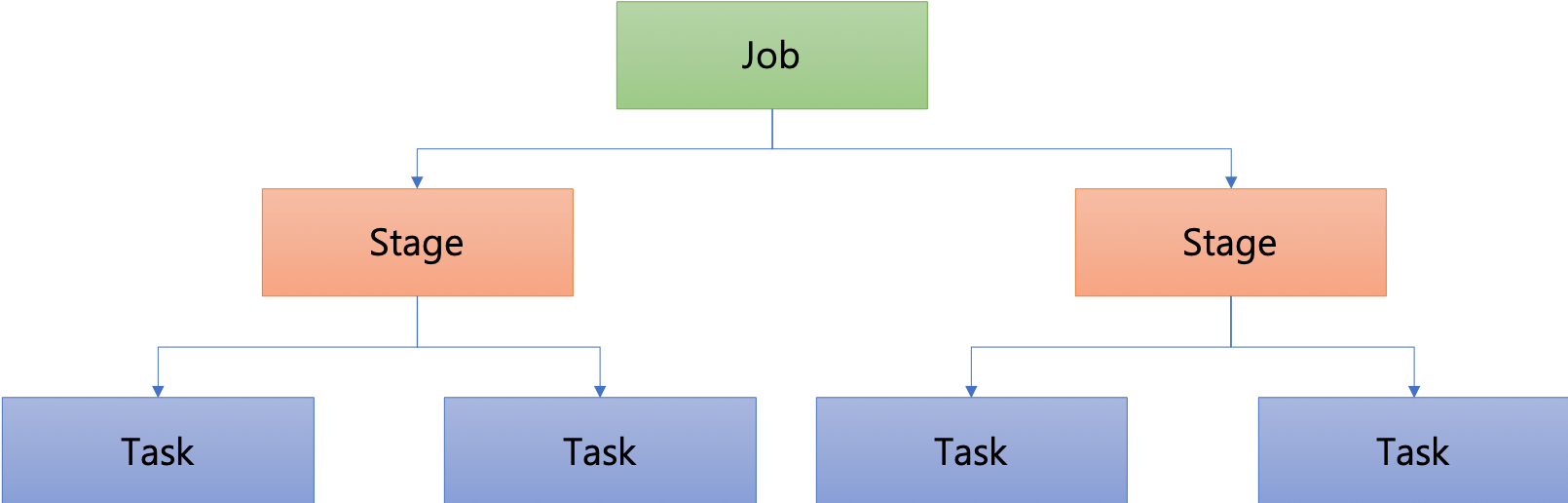
잡(Job)
스파크 애플리케이션으로 제출된 작업입니다.
스테이지(Stage)
잡을 작업의 단위에 따라 구분한 것이 스테이지입니다.
태스크(Task)
익스큐터에서 실행되는 실제 작업입니다. 데이터를 읽거나, 필터링 하는 실제 작업을 처리합니다.
클러스터 매니저
스파크는 여러 가지 클러스터 매니저를 지원합니다.
- YARN
- 하둡 클러스터 매니저
- 리소스 매니저, 노드 매니저로 구성 됨
- Mesos
- 동적 리소스 공유 및 격리를 사용하여 여러 소스의 워크로드를 처리
- 아파치의 클러스터 매니저
- 마스터와 슬레이브로 구성됨
- StandAlone
- 스파크에서 자체적으로 제공하는 클러스터 매니저
- 각 노드에서 하나의 익스큐터만 실행 가능
실행 방법
스파크 애플리케이션은 스칼라, 자바, 파이썬, R 로 구현할 수 있습니다. 각 언어로 스파크 SQL을 실행할 수도 있습니다. 스파크 애플리케이션은 jar 파일로 묶어서 실행하거나, REPL 환경에서 실행할 수 있습니다.
각 언어별 실행 스크립트 스파크를 다운로드 받아서 bin 디렉토리에 들어가면 다음과 같이 각 언어를 실행할 수 있는 스크립트를 확인할 수 있습니다. 각 스크립트로 실행가능한 언어는 스크립트의 이름으로 확인할 수 있습니다.
bin 폴더 실행 파일
-rwxr-xr-x 1 root root 1099 Nov 16 2016 beeline
-rw-r--r-- 1 root root 2143 Nov 16 2016 load-spark-env.sh
-rwxr-xr-x 1 root root 3265 Nov 16 2016 pyspark // 파이썬
-rwxr-xr-x 1 root root 1040 Nov 16 2016 run-example
-rwxr-xr-x 1 root root 3126 Nov 16 2016 spark-class
-rwxr-xr-x 1 root root 1049 Nov 16 2016 sparkR // R
-rwxr-xr-x 1 root root 3026 Nov 16 2016 spark-shell // scala repl
-rwxr-xr-x 1 root root 1075 Nov 16 2016 spark-sql // spark on sql
-rwxr-xr-x 1 root root 1050 Nov 16 2016 spark-submit // scala jar
스파크 애플리케이션 제출(spark-submit) 스칼라나, 자바로 작성한 스파크 애플리케이션을 jar 파일로 실행할 때나, 파이썬, R 파일을 spark-submit을 이용해 실행할 수 있습니다. 사용법1은 다음과 같습니다.
spark-submit 실행 옵션
$ ./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<app jar | python file | R file> \
[application-arguments]
클러스터 매니저가 yarn인 경우 실행 방법
JAR 파일 실행
$ spark-submit --master yarn \
--queue spark_queue \
--class sdk.spark.SparkWordCount \
--conf spark.shuffle.service.enabled=true \
./Spark-Example.jar
파이썬 파일 실행
$ spark-submit --master yarn \
--queue spark_queue \
./py01.py
설정값 spark-submit을 이용할 때의 설정값은 다음과 같습니다.
| 설정 | 비고 |
|---|---|
| --master | 클러스터 매니저 설정 |
| --deploy-mode | 드라이버의 디플로이 모드 설정 |
| --class | main 함수가 들어 있는 클래스 지정 |
| --name | 애플리케이션의 이름 지정. 스파크 웹 UI에 표시 |
| --jars | 애플리케이션 실행에 필요한 라이브러리 목록. 콤마로 구분 |
| --files | 애플리케이션 실행에 필요한 파일 목록 |
| --queue | 얀의 실행 큐이름 설정 |
| --executor-memory | 익스큐터가 사용할 메모리 바이트 용량. 512m. 1g 등도 사용 가능 |
| --driver-memory | 드라이버 프로세스가 사용할 메모리 바이트 용량. 512m. 1g 등도 사용 가능 |
| --num-executors | 익스큐터의 개수 설정 |
| --executor-cores | 익스큐터의 코어 개수 설정 |
디플로이 모드 디플로이 모드에 대한 설정값은 다음과 같습니다.
| 설정 | 비고 |
|---|---|
| client | 프로그램을 실행하는 노드에서 드라이버 실행 |
| cluster | 클러스터 내부의 노드에서 드라이버 실행 |
클러스터 매니저 설정 | 클러스터 매니저 설정은 다음과 같습니다.
| 설정 | 비고 |
|---|---|
| spark://ip:port | 스파크 스탠드얼론 클러스터 사용 |
| mesos://ip:port | 아파치 메조스 사용 |
| yarn | 하둡 얀 클러스터. HADOOP_CONF_DIR 설정 참조하여 처리 |
| local | 로컬모드에서 싱글코어로 실행 |
| local[N] | 로컬모드에서 N개 코어로 실행 |
스파크 애플리케이션 REPL 처리
스파크는 REPL 환경을 이용한 작업 처리도 지원합니다. spark-shell, pyspark를 실행하면 REPL 환경에서 인터랙티브하게 작업을 처리할 수 | 있습니다. spark-shell은 스칼라, pyspark는 파이썬을 지원합니다. 각 쉘을 실행할 때 옵션을 설정하여 클러스터 매니저를 지정할 수 있습니다.
spark-shell 환경 스칼라를 이용한 처리는 spark-shell 을 이용합니다.
$ spark-shell --master yarn --queue queue_name
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
19/01/03 08:40:29 WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
19/01/03 08:40:36 WARN SparkContext: Use an existing SparkContext, some configuration may not take effect.
Spark context Web UI available at http://127.0.0.1:4040
Spark context available as 'sc' (master = yarn, app id = application_1520227878653_37974).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.0.2
/_/
Using Scala version 2.11.8 (OpenJDK 64-Bit Server VM, Java 1.8.0_121)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
설정값 변경 설정값은 spark-submit과 같습니다. 아래와 같이 사용하면 됩니다.
jar 파일 추가
$ spark-shell --master yarn \
--queue queue_name \
--jars a.jar,b.jar,c.jar \
--conf spark.shuffle.service.enabled=true
익스큐터 개수 설정 스파크 쉘을 실행할 때 실행할 익스큐터의 개수와 메모리를 설정할 수 있습니다.
$ spark-shell \
--master yarn \
--deploy-mode client \
--driver-memory 2g \
--executor-memory 2g \
--executor-cores 1 \
--num-executors 5
pyspark 환경 파이썬을 이용한 처리는 pyspark를 이용합니다.
$ pyspark --master yarn --queue queue_name
Python 2.7.12 (default, Sep 1 2016, 22:14:00)
[GCC 4.8.3 20140911 (Red Hat 4.8.3-9)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
19/01/03 08:46:58 WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.0.2
/_/
Using Python version 2.7.12 (default, Sep 1 2016 22:14:00)
SparkSession available as 'spark'.
>>>
모니터링 스파크 컨텍스트가 초기화되면 모니터링을 위한 웹UI가 생성됩니다. 스파크 쉘을 실행하면 다음과 같이 웹 UI 주소를 확인할 수 있습니다. 여기서 애플리케이션의 실행 상황을 확인할 수 있습니다.
Spark context Web UI available at http://127.0.0.1:4040 spark web ui